コップの状態分析
Contents
処理方針
まずは加速度データ、磁気コンパスデータ、ジャイロセンサデータをplot そこからどのように動いたのかのおおよその検討をつける 使えそうなデータ全ての平均・最大・最小・分散・中央値・最頻値・標準偏差を計算(今回は3つとも) 入力・出力配列を作成しnprtoolを用いてデータの分類
テーブルとして読み込む
readGlassData2
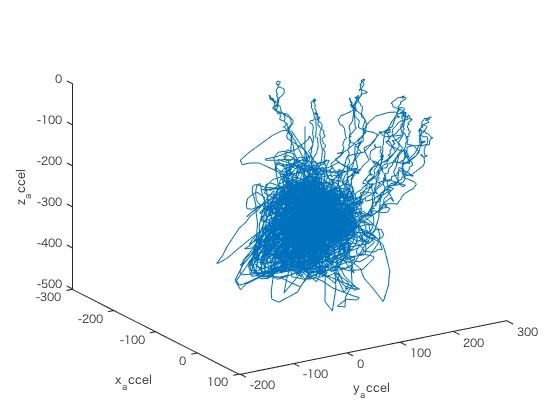
データを加速度の値の変化に注目して可視化してみる
figure ax = glassdata1.accelX; ay = glassdata1.accelY; az = glassdata1.accelZ; plot3(ax,ay,az); xlabel('x_accel'); ylabel('y_accel'); zlabel('z_accel'); view(58,26);
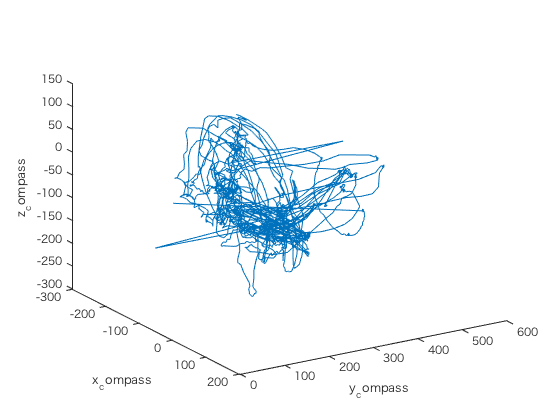
データを磁気コンパスの値の変化に注目可視化してみる
figure cx = glassdata1.compassX; cy = glassdata1.compassY; cz = glassdata1.compassZ; plot3(cx,cy,cz); xlabel('x_compass'); ylabel('y_compass'); zlabel('z_compass'); view(58,26);
データをジャイロセンサの値の変化に注目して可視化してみる
figure gx = glassdata1.gyroX; gy = glassdata1.gyroY; gz = glassdata1.gyroZ; plot3(gx,gy,gz); xlabel('x_gyro'); ylabel('y_gyro'); zlabel('z_gyro'); view(58,26);

データの総数や、ループの回数を計算する
numData = length(glassdata1.groupID); dataPerSample = 240; % サンプルごとの生データ数 3秒 samplingInterval = 160; % サンプル生成間隔 2秒 numSample = (numData-dataPerSample)/samplingInterval; % サンプル数
state文字列をインデックスに変換
[statenum,statenames]=grp2idx(glassdata1.state);
2秒間隔で過去3秒間を代表するデータを作成する
2秒間隔で3秒の最大最小平均分散中央値最頻値標準偏差を計算 期間の80%以上同じ状態の場合は、それをその期間の状態として設定 80%に満たない場合は、6(stateの種類+1)とする
for n = 1:numSample startSample = (n-1)*samplingInterval+1; endSample = startSample+dataPerSample; ax_mean(n)=mean(ax(startSample:endSample)); ay_mean(n)=mean(ay(startSample:endSample)); az_mean(n)=mean(az(startSample:endSample)); ax_min(n)=min(ax(startSample:endSample)); ay_min(n)=min(ay(startSample:endSample)); az_min(n)=min(az(startSample:endSample)); ax_max(n)=max(ax(startSample:endSample)); ay_max(n)=max(ay(startSample:endSample)); az_max(n)=max(az(startSample:endSample)); ax_var(n)=var(ax(startSample:endSample)); ay_var(n)=var(ay(startSample:endSample)); az_var(n)=var(az(startSample:endSample)); ax_median(n)=median(ax(startSample:endSample)); ay_median(n)=median(ay(startSample:endSample)); az_median(n)=median(az(startSample:endSample)); ax_mode(n)=mode(ax(startSample:endSample)); ay_mode(n)=mode(ay(startSample:endSample)); az_mode(n)=mode(az(startSample:endSample)); ax_std(n)=std(ax(startSample:endSample)); ay_std(n)=std(ay(startSample:endSample)); az_std(n)=std(az(startSample:endSample)); cx_mean(n)=mean(cx(startSample:endSample)); cy_mean(n)=mean(cy(startSample:endSample)); cz_mean(n)=mean(cz(startSample:endSample)); cx_min(n)=min(cx(startSample:endSample)); cy_min(n)=min(cy(startSample:endSample)); cz_min(n)=min(cz(startSample:endSample)); cx_max(n)=max(cx(startSample:endSample)); cy_max(n)=max(cy(startSample:endSample)); cz_max(n)=max(cz(startSample:endSample)); cx_var(n)=var(cx(startSample:endSample)); cy_var(n)=var(cy(startSample:endSample)); cz_var(n)=var(cz(startSample:endSample)); cx_median(n)=median(cx(startSample:endSample)); cy_median(n)=median(cy(startSample:endSample)); cz_median(n)=median(cz(startSample:endSample)); cx_mode(n)=mode(cx(startSample:endSample)); cy_mode(n)=mode(cy(startSample:endSample)); cz_mode(n)=mode(cz(startSample:endSample)); cx_std(n)=std(cx(startSample:endSample)); cy_std(n)=std(cy(startSample:endSample)); cz_std(n)=std(cz(startSample:endSample)); gx_mean(n)=mean(gx(startSample:endSample)); gy_mean(n)=mean(gy(startSample:endSample)); gz_mean(n)=mean(gz(startSample:endSample)); gx_min(n)=min(gx(startSample:endSample)); gy_min(n)=min(gy(startSample:endSample)); gz_min(n)=min(gz(startSample:endSample)); gx_max(n)=max(gx(startSample:endSample)); gy_max(n)=max(gy(startSample:endSample)); gz_max(n)=max(gz(startSample:endSample)); gx_var(n)=var(gx(startSample:endSample)); gy_var(n)=var(gy(startSample:endSample)); gz_var(n)=var(gz(startSample:endSample)); gx_median(n)=median(gx(startSample:endSample)); gy_median(n)=median(gy(startSample:endSample)); gz_median(n)=median(gz(startSample:endSample)); gx_mode(n)=mode(gx(startSample:endSample)); gy_mode(n)=mode(gy(startSample:endSample)); gz_mode(n)=mode(gz(startSample:endSample)); gx_std(n)=std(gx(startSample:endSample)); gy_std(n)=std(gy(startSample:endSample)); gz_std(n)=std(gz(startSample:endSample)); [m,f] = mode(statenum(startSample:endSample)); if f >= dataPerSample*0.5 stateN(n) = m; else stateN(n) = length(statenames); end end clearvars m f
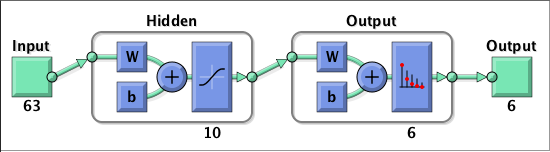
入力・出力配列の作成
inputData=[ax_mean' ay_mean' az_mean'... ax_min' ay_min' az_min'... ax_max' ay_max' az_max'... ax_var' ay_var' az_var'... ax_median' ay_median' az_median'... ax_mode' ay_mode' az_mode'... ax_std' ay_std' az_std'... cx_mean' cy_mean' cz_mean'... cx_min' cy_min' cz_min'... cx_max' cy_max' cz_max'... cx_var' cy_var' cz_var'... cx_median' cy_median' cz_median'... cx_mode' cy_mode' cz_mode'... cx_std' cy_std' cz_std'... gx_mean' gy_mean' gz_mean'... gx_min' gy_min' gz_min'... gx_max' gy_max' gz_max'... gx_var' gy_var' gz_var'... gx_median' gy_median' gz_median'... gx_mode' gy_mode' gz_mode'... gx_std' gy_std' gz_std']; outputData=stateN'; outputs=zeros(length(outputData),length(statenames)); for n=1:length(outputData) row=outputData(n); outputs(n,row)=1; end
生成されたニューラルネットを試してみてみる
makenet; rng(0); r=randi([1 length(outputData)],1,10); testdata=inputData(r,:)'; results=net(testdata); [maxval,maxind]=max(results); [statenames(maxind) statenames(outputData(r))]
performance =
0.0357
ans =
'holdingByHand' 'holdingByHand'
'toast' 'toast'
'holdingByHand' 'holdingByHand'
'onTable' 'toast'
'toast' 'toast'
'holdingByHand' 'holdingByHand'
'walking' 'walking'
'onTable' 'onTable'
'holdingByHand' 'holdingByHand'
'holdingByHand' 'holdingByHand'

Confusionとの比較

処理結果
入力データの数を増やした処理を行った その結果、訓練データや検証データに対しては正答率の向上が見られ、テストデータに対しては逆に低下した 訓練データは約5%ほど、検証データは約15%ほどの向上が見られた テストデータは約5%ほどの低下が見られた 訓練データに対して向上が見られた理由としては、訓練データは学習に用いたデータであるため、抽出データの種類を増やすとそれだけそのデータのアイデンティティーが際立つからだと思われる 検証データの向上から、データを増やしたら過学習によるズレが減少していることが分かる テストデータの結果が低下しているのは、検証データによって反対に過学習が促進されてしまったからであろうか